Install Your Local AI Assistant#
If you wish to install your own artificial intelligence assistant on your device, free of charge, without creating accounts, exposing your data, and all under your control, this is possible thanks to Ollama. Available for Windows, Linux, and Mac. I will explain how you can obtain the assistants for Qwen, Llama, and Deepseek.
Hardware Requirements for Your AI Assistant#
The first thing we need to consider is that Ollama does not have specific hardware requirements; these depend on the language (or artificial intelligence) models you plan to use. The most important factor in determining these requirements is the number of parameters in the model, which you will typically see mentioned as billions or trillions. Large Language Models (LLMs) available in commercial services have trillions of parameters and require servers with not just a great CPU power but also GPU. If the model is of billions of parameters, it’s possible to consider using local machines (our computers), but if they are close to 100 billions, you will need cutting-edge hardware with RAM over 64 GB and several RTX graphics cards. Between 4 billions and 20 billions of parameters, you can consider their use on gaming machines, from a single RTX graphics card (series 2000 and later) and 16 GB of RAM, as is my case (but more than 10 billions run forcefully and even generate the closure of open applications). If your machine does not have a GPU but has at least 16 GB of RAM, you could use models with fewer than 4 billions of parameters smoothly. The lesser the number of parameters, the less hardware resource required, but also these are lower-precision models.
Atención
With the release of deepseek-r1, there has been much discussion about its
economic benefits and ease of local execution, however, this is important
regarding model training and not concerning model inference. The lightweight
models of deepseek-r1 are distilled versions of Qwen and Llama, so if
Deepseek works for you, the originals will work as well, and in my opinion,
they are better.
Installing Ollama#
To install Ollama, if you use Mac or Windows, you can use the downloadable installers available on their website, but if you use Linux, you can run directly in your console:
curl -fsSL https://ollama.com/install.sh | sh
This will take a few minutes and detect the appropriate graphics card configuration if we have one.
Once finished, we will have the language model manager ready to install and run our first model.
Installing a Language Model with Ollama#
But which language models can we install? We have access to the models published on the official Ollama website in the model search section. The main families we can identify are:
Qwen: Family of models produced by Alibaba (China). I highlight the capabilities of the 2.5 series, which include general and code models.
Mistral: Family of models produced by Mistral AI, very close to the academic community with a strong open source commitment from the start. I highlight the math-specialized model.
Phi: Family of models produced by Microsoft. An interesting bet from Microsoft with “lightweight” models that have maximum capabilities.
Llama: Family of models produced by Meta (Facebook). The path with the 3.2 series is highlighted for lightweight models and its code assistant “Codellama”.
Deepseek: Family of models produced by Deepseek, a company under the High-Flyer umbrella (China). I must say that my experience with deepseek has not been good; it confuses language, takes complex paths to simple problems, and is less precise. However, I find its default behavior of showing the “reasoning” before the final answer interesting, and in response to very clear instructions, it can be easily guided.
To install and run a language model, we proceed with the run option of
ollama, indicating the name of the model and the number of parameters
separated by :, and if no number of parameters is indicated, it will take the
default version. For example, to install Qwen2.5 with 7 billion parameters, you
would do:
ollama run qwen2.5:7b
This instruction can be seen on the model page when selecting the number of parameters from the list on the right.
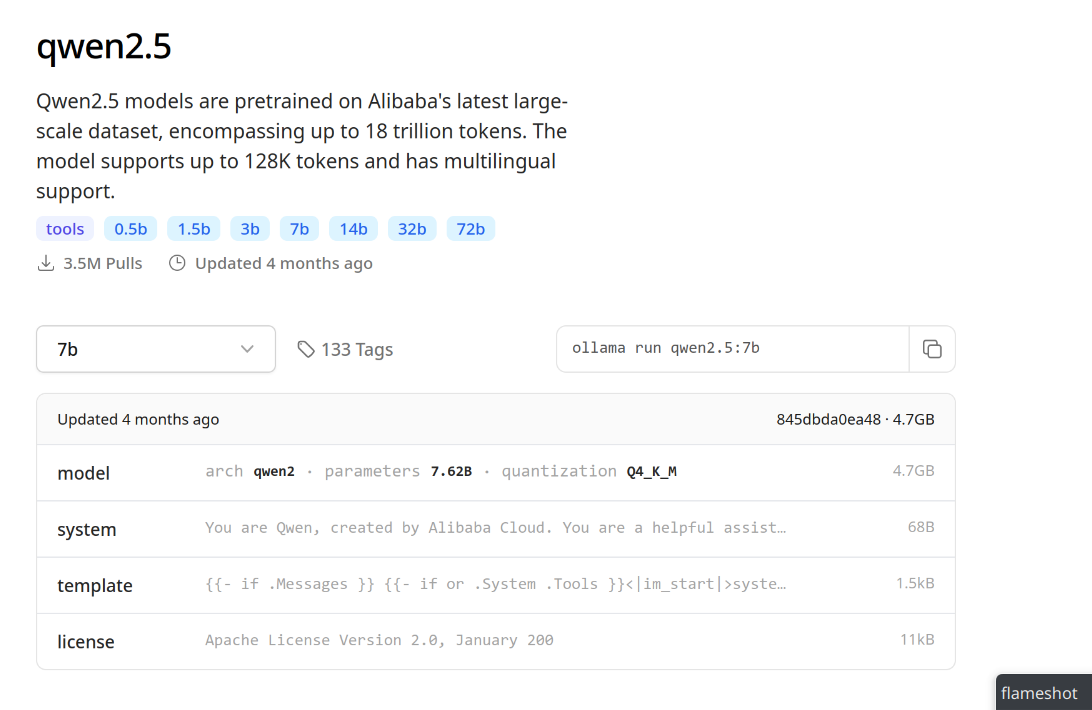
Information about the Qwen2.5 model on Ollama’s website.#
Other examples could be:
ollama run llama3.2:3b
ollama run phi3.5
ollama run deepseek-r1:7b
Query Your Artificial Intelligence Assistant#
Once installed, it enables the console for query entry. But if we want to go
back, we can simply run it again with the run option. Example:
ollama run qwen2.5:7b
We write our query and press Enter ↵.
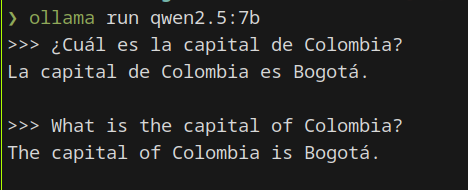
Query with the Qwen2.5 language model in Spanish and English.#
If you want to exit any assistant with Ollama, you should type /bye and press
Enter ↵.
Other Useful Ollama Options#
If you want to list the installed models, you can run ollama list, and to
delete a model that you no longer need (and free up disk space), you can use
ollama rm followed by the name of the model as listed with ollama list. For
example, ollama rm deepseek-r1:14b.
ChatGPT-like Web Interface#
The terminal is not user-friendly for all users, so you can install Open WebUI and have a chat interface similar to ChatGPT that allows you to organize conversations, add collections of knowledge files used for analyzing or answering questions about them, and select the model you want to use for a specific conversation. It also offers a testing option that lets you evaluate the different models you have installed.
If you have uv installed, you can install it with the following command:
uv tool install --python 3.11 open-webui
After that, start the local server with open-webui serve. Use the URL
indicated upon execution to paste into your browser’s address bar (by default,
it is http://0.0.0.0:8080).
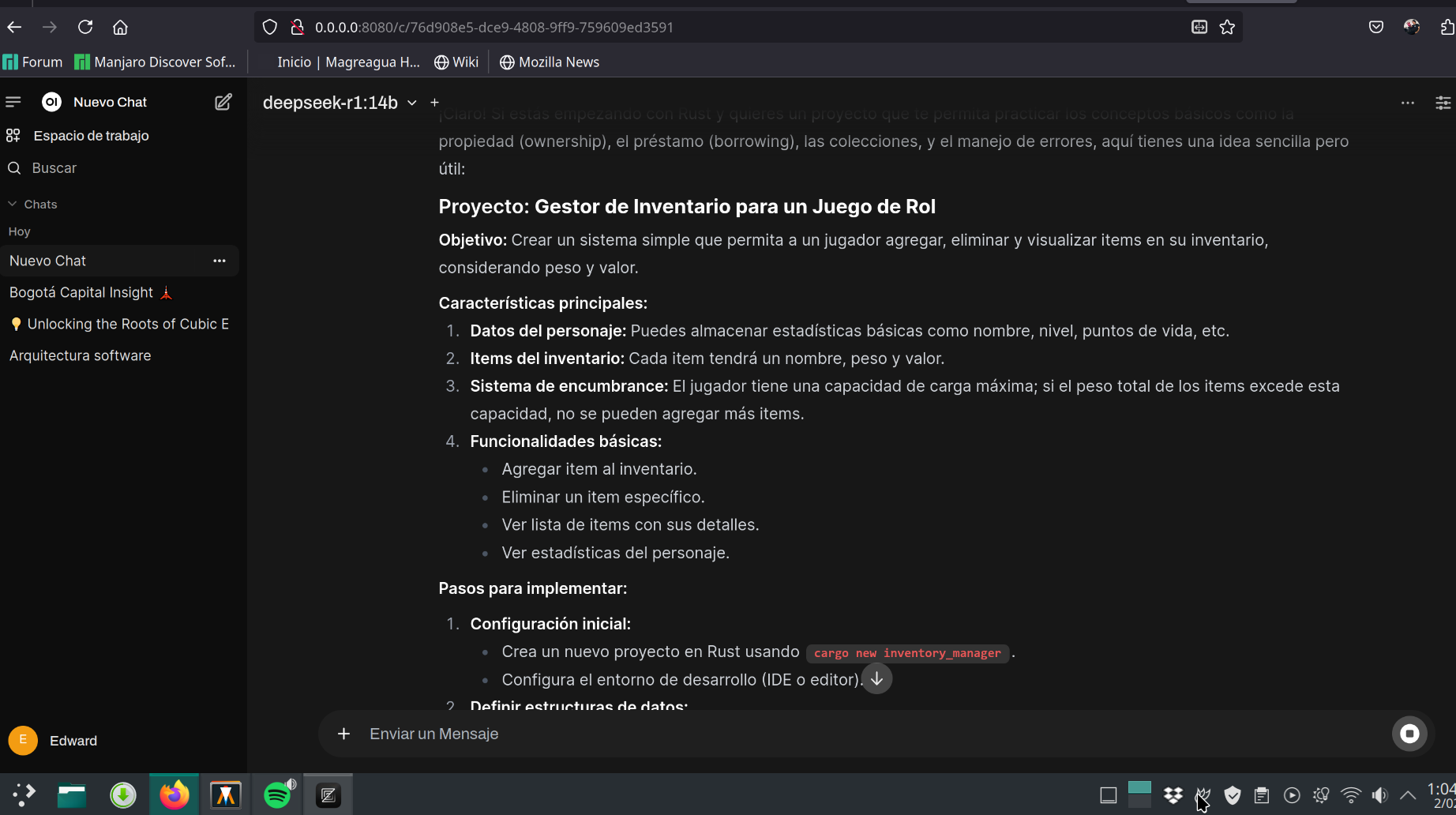
Preview of Open Web UI in organizing conversations with language models.#